Extraction
![]()
Open In Collab
Use case
Getting structured output from raw LLM generations is hard.
For example, suppose you need the model output formatted with a specific schema for:
- Extracting a structured row to insert into a database
- Extracting API parameters
- Extracting different parts of a user query (e.g., for semantic vs keyword search)
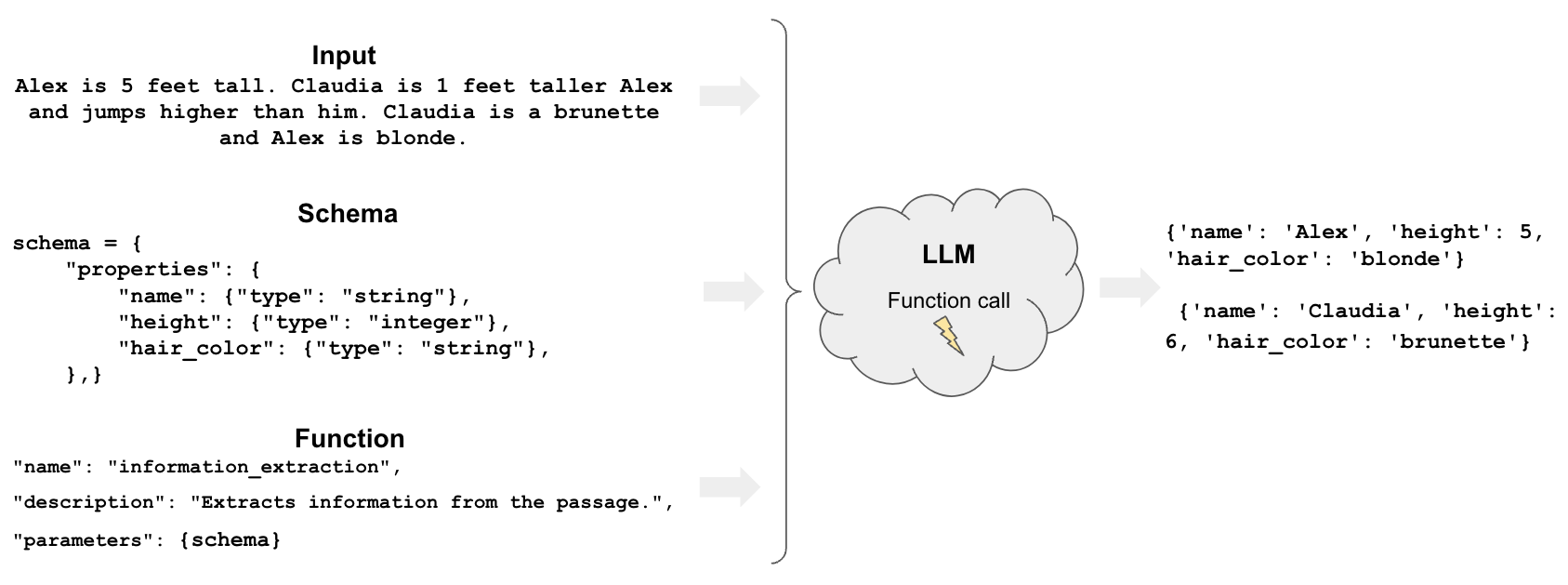
Overview
There are two primary approaches for this:
Functions: Some LLMs can call functions to extract arbitrary entities from LLM responses.Parsing: Output parsers are classes that structure LLM responses.
Only some LLMs support functions (e.g., OpenAI), and they are more general than parsers.
Parsers extract precisely what is enumerated in a provided schema (e.g., specific attributes of a person).
Functions can infer things beyond of a provided schema (e.g., attributes about a person that you did not ask for).
Quickstart
OpenAI functions are one way to get started with extraction.
Define a schema that specifies the properties we want to extract from the LLM output.
Then, we can use create_extraction_chain to extract our desired schema
using an OpenAI function call.
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
from langchain.chains import create_extraction_chain
from langchain.chat_models import ChatOpenAI
# Schema
schema = {
"properties": {
"name": {"type": "string"},
"height": {"type": "integer"},
"hair_color": {"type": "string"},
},
"required": ["name", "height"],
}
# Input
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
# Run chain
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
chain = create_extraction_chain(schema, llm)
chain.run(inp)
[{'name': 'Alex', 'height': 5, 'hair_color': 'blonde'},
{'name': 'Claudia', 'height': 6, 'hair_color': 'brunette'}]
Option 1: OpenAI functions
Looking under the hood
Let’s dig into what is happening when we call create_extraction_chain.
The LangSmith
trace
shows that we call the function information_extraction on the input
string, inp.
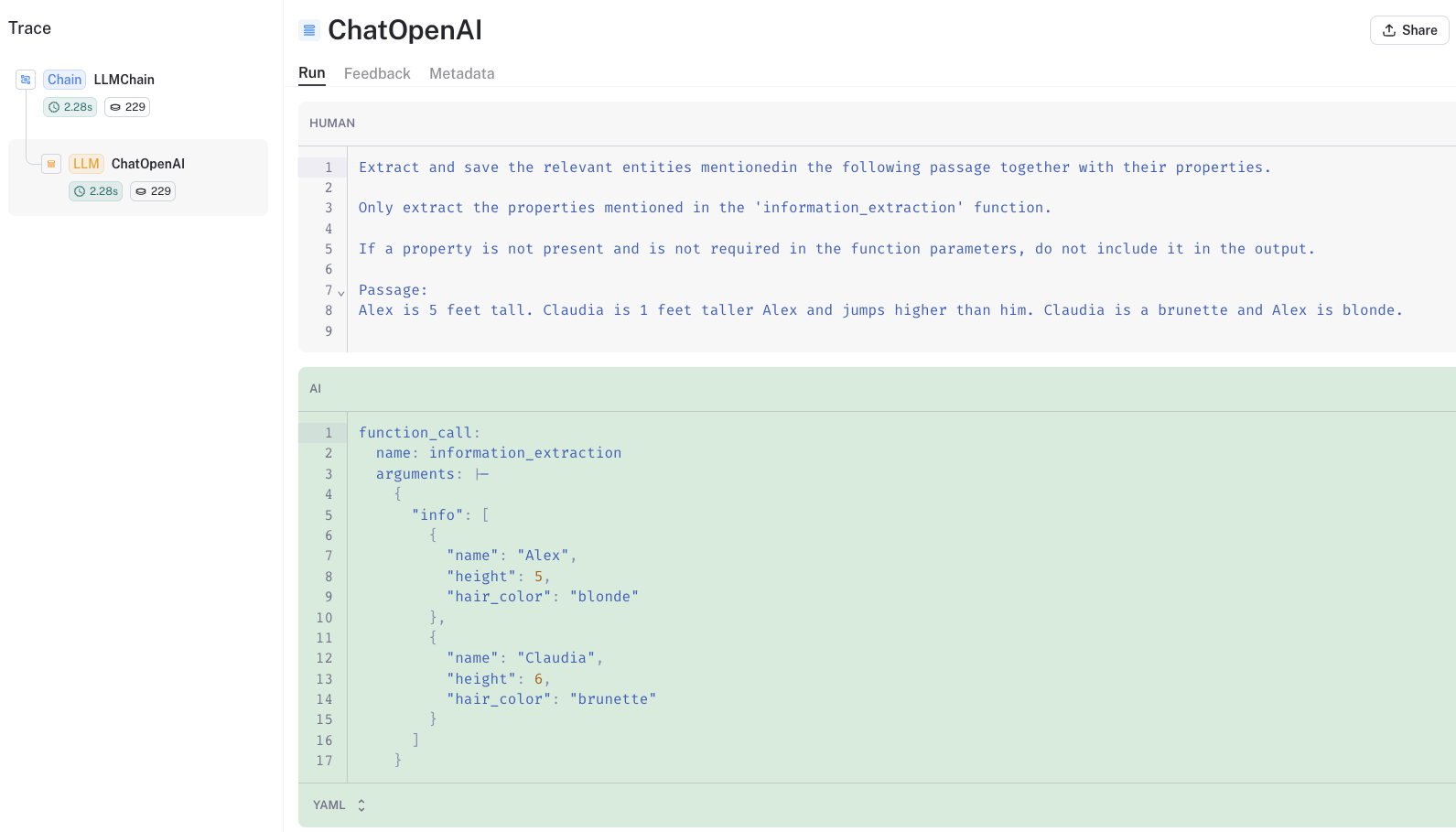
This information_extraction function is defined
here
and returns a dict.
We can see the dict in the model output:
{
"info": [
{
"name": "Alex",
"height": 5,
"hair_color": "blonde"
},
{
"name": "Claudia",
"height": 6,
"hair_color": "brunette"
}
]
}
The create_extraction_chain then parses the raw LLM output for us
using
JsonKeyOutputFunctionsParser.
This results in the list of JSON objects returned by the chain above:
[{'name': 'Alex', 'height': 5, 'hair_color': 'blonde'},
{'name': 'Claudia', 'height': 6, 'hair_color': 'brunette'}]
Multiple entity types
We can extend this further.
Let’s say we want to differentiate between dogs and people.
We can add person_ and dog_ prefixes for each property
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
},
"required": ["person_name", "person_height"],
}
chain = create_extraction_chain(schema, llm)
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.
Alex's dog Frosty is a labrador and likes to play hide and seek."""
chain.run(inp)
[{'person_name': 'Alex',
'person_height': 5,
'person_hair_color': 'blonde',
'dog_name': 'Frosty',
'dog_breed': 'labrador'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'}]
Unrelated entities
If we use required: [], we allow the model to return only person
attributes or only dog attributes for a single entity (person or
dog).
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
},
"required": [],
}
chain = create_extraction_chain(schema, llm)
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.
Willow is a German Shepherd that likes to play with other dogs and can always be found playing with Milo, a border collie that lives close by."""
chain.run(inp)
[{'person_name': 'Alex', 'person_height': 5, 'person_hair_color': 'blonde'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'},
{'dog_name': 'Willow', 'dog_breed': 'German Shepherd'},
{'dog_name': 'Milo', 'dog_breed': 'border collie'}]
Extra information
The power of functions (relative to using parsers alone) lies in the ability to perform semantic extraction.
In particular,
we can ask for things that are not explicitly enumerated in the schema.
Suppose we want unspecified additional information about dogs.
We can use add a placeholder for unstructured extraction,
dog_extra_info.
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
"dog_extra_info": {"type": "string"},
},
}
chain = create_extraction_chain(schema, llm)
chain.run(inp)
[{'person_name': 'Alex', 'person_height': 5, 'person_hair_color': 'blonde'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'},
{'dog_name': 'Willow',
'dog_breed': 'German Shepherd',
'dog_extra_info': 'likes to play with other dogs'},
{'dog_name': 'Milo',
'dog_breed': 'border collie',
'dog_extra_info': 'lives close by'}]
This gives us additional information about the dogs.
Pydantic
Pydantic is a data validation and settings management library for Python.
It allows you to create data classes with attributes that are automatically validated when you instantiate an object.
Lets define a class with attributes annotated with types.
from typing import Optional
from langchain.chains import create_extraction_chain_pydantic
from langchain_core.pydantic_v1 import BaseModel
# Pydantic data class
class Properties(BaseModel):
person_name: str
person_height: int
person_hair_color: str
dog_breed: Optional[str]
dog_name: Optional[str]
# Extraction
chain = create_extraction_chain_pydantic(pydantic_schema=Properties, llm=llm)
# Run
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
chain.run(inp)
[Properties(person_name='Alex', person_height=5, person_hair_color='blonde', dog_breed=None, dog_name=None),
Properties(person_name='Claudia', person_height=6, person_hair_color='brunette', dog_breed=None, dog_name=None)]
As we can see from the
trace,
we use the function information_extraction, as above, with the
Pydantic schema.
Option 2: Parsing
Output parsers are classes that help structure language model responses.
As shown above, they are used to parse the output of the OpenAI function
calls in create_extraction_chain.
But, they can be used independent of functions.
Pydantic
Just as a above, let’s parse a generation based on a Pydantic data class.
from typing import Optional, Sequence
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import (
PromptTemplate,
)
from pydantic import BaseModel, Field, validator
class Person(BaseModel):
person_name: str
person_height: int
person_hair_color: str
dog_breed: Optional[str]
dog_name: Optional[str]
class People(BaseModel):
"""Identifying information about all people in a text."""
people: Sequence[Person]
# Run
query = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=People)
# Prompt
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Run
_input = prompt.format_prompt(query=query)
model = OpenAI(temperature=0)
output = model(_input.to_string())
parser.parse(output)
People(people=[Person(person_name='Alex', person_height=5, person_hair_color='blonde', dog_breed=None, dog_name=None), Person(person_name='Claudia', person_height=6, person_hair_color='brunette', dog_breed=None, dog_name=None)])
We can see from the LangSmith trace that we get the same output as above.
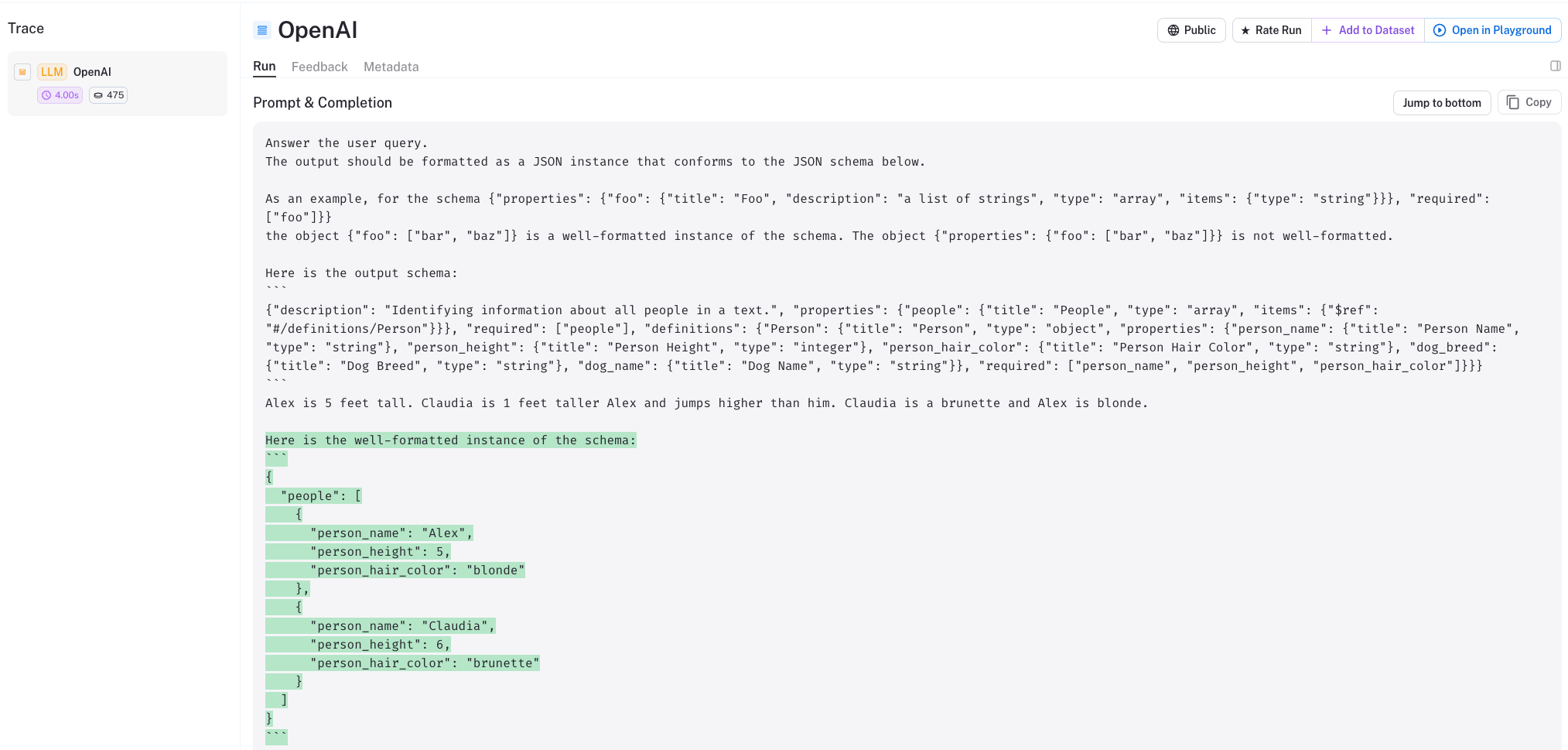
We can see that we provide a two-shot prompt in order to instruct the LLM to output in our desired format.
And, we need to do a bit more work:
- Define a class that holds multiple instances of
Person - Explicitly parse the output of the LLM to the Pydantic class
We can see this for other cases, too.
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import (
PromptTemplate,
)
from pydantic import BaseModel, Field, validator
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# And a query intended to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
# Prompt
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Run
_input = prompt.format_prompt(query=joke_query)
model = OpenAI(temperature=0)
output = model(_input.to_string())
parser.parse(output)
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
As we can see, we get an output of the Joke class, which respects our
originally desired schema: ‘setup’ and ‘punchline’.
We can look at the LangSmith trace to see exactly what is going on under the hood.

Going deeper
- The output parser documentation includes various parser examples for specific types (e.g., lists, datetime, enum, etc).
- The experimental Anthropic function calling support provides similar functionality to Anthropic chat models.
- LlamaCPP natively supports constrained decoding using custom grammars, making it easy to output structured content using local LLMs
- JSONFormer offers another way for structured decoding of a subset of the JSON Schema.
- Kor is another library for extraction where schema and examples can be provided to the LLM.